安装 KOReader 的前提是 Kindle 设备必须Jail Break,并安装Kindle的MRPI(MobileRead Package Install...
Kobo Libra 2 + KOReader 的组合从使用体验上和便利性上确实比Kindle系列产品要好,mobi格式基本可以舍弃了。 屏幕显示,Kobo L...
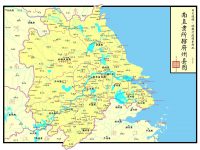
《铁血残明》一书中,各战役的详细经过需要配合地图才能明确具体的位置和动线,几张备查地图如下。 南直隶所辖州府县图 桐城县图 安庆府地图 滁州之战态势图 宿松之战...
5批次3610项国家级非物质文化遗产中,饮食类为165项,明细整理如下。
家庭应急物资储备建议清单(基础版) 序号 分类 物品名称 相关说明 适用灾害类型 1 应急物品 饮用水 包括瓶(桶)装水等,用于补充人体水分,满足一家人 48 ...
关于本站文章皆为原创,欢迎转载,请注出处。
XAMPP控制面板简体中文汉化
2012-10-25阅读(6149)
InfoQ第三季度原创新闻汇总
2007-11-21阅读(5254)
健康和医疗信息项目GNU Health
2012-05-04阅读(5073)
word表格复制到excel中消除多行
2022-11-07阅读(4595)
开源GIS项目OpenJUMP简介
2009-06-20阅读(4177)
 工作与兴趣记录本
工作与兴趣记录本